一、scrapy简介
Scrapy,一个爬虫框架,使用起来非常高效,只需要关注页面解析,存储方式等,不需要再重新开发网络模块。架构图如下。
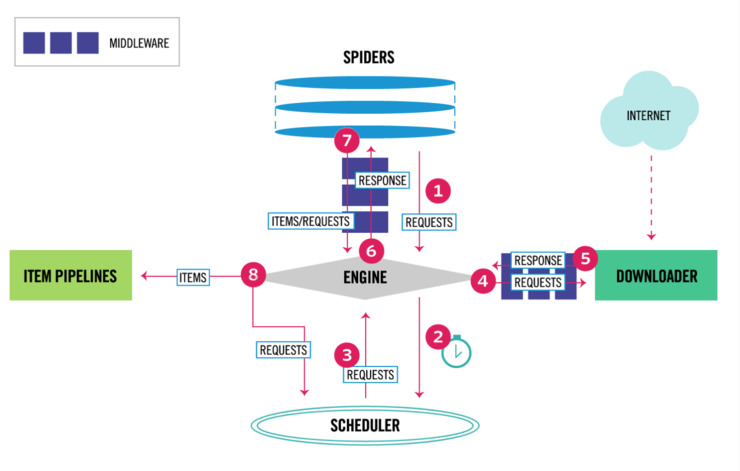
根据实际用途解释架构的几个模块:
ENGINE:scrapy爬虫框架内核,用于调用其他模块。
SPIDERS:爬虫模块,用户解析网页内容,生成新的请求或需要存储的数据。
ITEM:存储模块,用于定制结构化的数据。
PIPELINES:管道模块,ITEM结构化的数据会经过它,在它里面保持到不同的底层组件,如redis,mysql等。
SCHEDULER:调度器,保存着SPIDERS生成的REQUESTS请求对象,当ENGINE需要爬数据时,从它这里获取。
DOWNLOADER:下载器,ENGINE从SCHEDULER拿到REQUESTS请求后,交给它去从互联网下载,下载生成RESPONSE响应对象。响应对象会被ENGINE交给SPIDERS解析。
二、scrapy是如何爬取数据的
了解了各个模块,现在就根据图中的数字来说明scrapy是怎么工作的。
SPIDERS里面会有我们设置好的初始URL,SPIDERS会使用这些URL生成REQUEST请求对象,交给ENGINE。
ENGINE拿到REQUEST,存储到SCHEDULER中。
ENGINE需要开始爬取数据,于是从SCHEDULER拿REQUEST。
ENGINE拿到REQUEST后,交给DOWNLOADER下载。
DOWNLOADER通过REQUEST获取到RESPONSE后,把相应交给ENGINE。在4-5之间有紫色的方块,那是DOWNLOAD MIDDLEWARES中间件,用来处理ENGINE传来REQUEST和DOWNLOADER返回的RESPONSE。例如我不想用DOWNLOADER模块,于是就在这个地方自己拦截REQUEST,然后用自己的方式请求数据并返回RESPONSE给ENGINE。
ENGINE拿到RESPONSE后把它交给SPIDERS,我们就在SPIDERS里面开发我们自己的解析网页代码,把需要的数据请求解析出来。
解析出来的数据交给ENGINE。
ENGINE根据SPIDERS给的数据做不同处理:如果是ITEM结构化数据就交给PIPELINES,存储到底层组件;如果是REQUEST对象,就交给SCHEDULER,等待被获取抓取数据。
PIPELINES从步骤8中拿到的ITEMS解析并存储到自己需要的底层组件里,如redis,mysql等。
SCHEDULER从步骤8中拿到的REQUEST存储到自己的队列里,等待ENGINE获取。
三、安装scrapy
根据不同系统有不同的安装方式,但最通用的还是使用pip安装。
1
vagrant@vagrant-ubuntu-trusty-64:~$ sudo pip3 install scrapy
当然,由于优秀的软件包依赖问题,一般你是不可能一条命令安装成功的,根据错误原因,需要自己处理依赖问题。
四、开始使用scrapy爬取数据
1. xpath
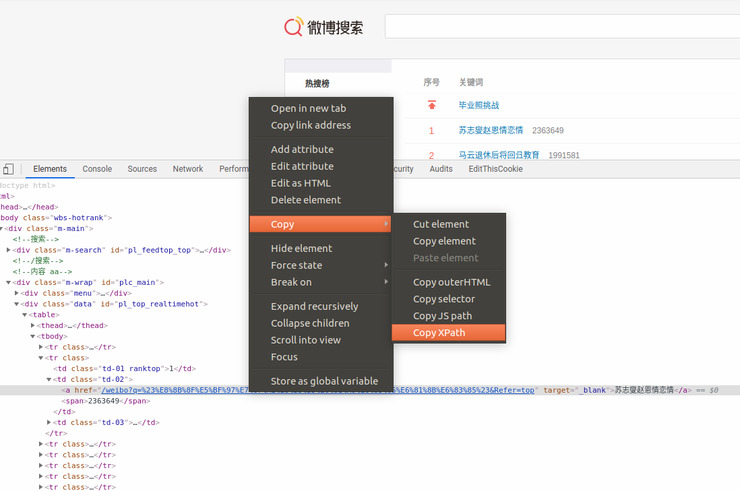
首先需要了解一下xpath,它是html标签选择器,用于快速定位html标签。chrome或firefox可以直接打开“开发者工具”,在element标签下右击需要的节点,可以直接复制xpath地址,类似这样//*[@id="pl_top_realtimehot"]/table/tbody/tr[2]/td[2]/a。
2. scrapy shell
这是scrapy的一个工具,方便测试下载下来的网页。
1
2
3
liuxu:weibo$ scrapy shell "https://s.weibo.com/top/summary?cate=realtimehot/"
>>> response.xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr[2]/td[2]/a').extract_first()
'<a href="/weibo?q=%23%E8%8B%8F%E5%BF%97%E7%87%AE%E8%B5%B5%E6%81%A9%E6%83%85%E6%81%8B%E6%83%85%23&Refer=top" target="_blank">苏志燮赵恩情恋情</a>'
3. 创建spider爬取数据
这里我以微博热搜为例,目标网址为https://s.weibo.com/top/summary?cate=realtimehot/。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
liuxu:scrapy$ scrapy startproject weibo
liuxu:scrapy$ tree weibo/
weibo/
├── scrapy.cfg
└── weibo
├── __init__.py
├── items.py
├── middlewares.py
├── pipelines.py
├── __pycache__
├── settings.py
└── spiders
├── __init__.py
└── __pycache__
4 directories, 7 files
目录中scrapy.cfg为基础配置文件,weibo/items.py为item模块文件,里面编写自己的结构化数据类。weibo/middlewares.py为中间件模块文件。weibo/pipelines.py为管道模块文件。weibo/settings.py为爬虫框架配置文件。weibo/spiders/目录下保存所有爬虫文件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
liuxu:weibo$ scrapy genspider weibo "https://s.weibo.com/top/summary?cate=realtimehot/"
Cannot create a spider with the same name as your project
liuxu:weibo$ tree .
.
├── scrapy.cfg
└── weibo
├── __init__.py
├── items.py
├── middlewares.py
├── pipelines.py
├── __pycache__
│ ├── __init__.cpython-36.pyc
│ └── settings.cpython-36.pyc
├── settings.py
└── spiders
├── __init__.py
├── __pycache__
│ └── __init__.cpython-36.pyc
└── resou.py
4 directories, 11 files
liuxu:weibo$ cat weibo/spiders/resou.py
# -*- coding: utf-8 -*-
import scrapy
class ResouSpider(scrapy.Spider):
name = 'resou'
allowed_domains = ['https://s.weibo.com/top/summary?cate=realtimehot/']
start_urls = ['http://https://s.weibo.com/top/summary?cate=realtimehot//']
def parse(self, response):
pass
看到新建了一个爬虫文件,然后我们编辑它:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
liuxu:weibo$ cat weibo/spiders/resou.py
# -*- coding: utf-8 -*-
import scrapy
class ResouSpider(scrapy.Spider):
name = 'resou'
allowed_domains = ['s.weibo.com']
start_urls = ['https://s.weibo.com/top/summary?cate=realtimehot/']
def parse(self, response):
tr_list = response.xpath("//*[@id='pl_top_realtimehot']/table/tbody/tr")
for index, tr in enumerate(tr_list):
if index == 0:
rank = 0
else:
rank = int(tr.xpath(".//td[position()=1]/text()").extract_first(default = 0))
title = tr.xpath(".//td[position()=2]/a/text()").extract_first(default = '-')
link = "https://s.weibo.com" + tr.xpath(".//td[position()=2]/a/@href").extract_first(default = '-')
count = int(tr.xpath(".//td[position()=2]/span/text()").extract_first(default = 0))
state = tr.xpath(".//td[position()=3]/i/text()").extract_first(default = '')
yield {"rank": rank, "title": title, "link": link, "count": count, "state": state}
liuxu:weibo$ scrapy runspider weibo/spiders/resou.py -o resou.json
这样就可以把输出爬取存储到当前目录的resou.json文件里的。
四、总结
这里只是一个简单的讲解,更负责的可以在PIPELINES模块里开发redis存储模块,在DOWNLOAD MIDDLEWARES里使用chrome driver --headless模式获取动态加载的网页等。
