一、简介
现代互联网服务庞大且复杂,且存在开发人员迭代,能力参差不齐,文档和代码脱节等问题。对于长年维护一个项目,复杂bug快速修复解决、新人接手项目、项目整体监控等存在诸多困难,费时费力。本文为伫立于解决这些问题提供一些帮助。
本文关键字:opentelemetry,granafa,loki,tempo/jaeger,APM(Application Performance Monitoring),RUM(Real User Monitoring)。
从一个bug出发
某文章编辑应用介绍
有一个文章编辑应用,前端是vue spa(单页面应用),后端是php/laravel提供接口。
用户登录后,点击进入某文章编辑页面,页面会异步调用读取该文章的接口,文章接口返回内容后加载到编辑页面。用户修改后可点击保存,此时请求接口提交修改。或者点击取消,放弃此次修改。
用户报告bug
某用户在登录点击某文章编辑后,文章编辑框中的内容被加载出来后,然后自动被删。退出再进入文章编辑框都是空内容。
bug的一般解决步骤
- 复现bug。
- 分析代码,将代码和各种因素结合分析(如网络、设备硬件资源等),联系代码逻辑和因素存在的抽象关系,分析并推理出bug的原因。
- 修复代码,以满足在目标环境的正常运行。
- 上线。
此bug的原因
- 第一次用户访问文章1,加载文章内容到编辑面板,包含标题、时间、文章内容等信息。其中article为文章model,article.title、article.content等和相关dom绑定。
- 用户退出编辑页面,进入文章2编辑页面,页面加载文章1缓存(导致bug的主要现象),清空article.content(文章内容自动被删的现象),然后做文章2接口请求。
- 此时由于用户网络极慢,文章2接口一直无返回,所以用户看到的一直是文章1丢失content的页面。
修复bug困难的地方
对于简单能随时复现的bug,应该感到庆幸。但我们经常遇到如本次相同无法复现的bug。更困难的情况,假如我无法review前端代码,只凭借以往经验分析推理实际环境,这个bug基本无法复现。
总之实际生产环境中非常复杂。
简单举例,有以下几点:
用户网络环境问题(本地DNS故障,城区运营商节点故障,流量/wifi切换,网络信号不好)。
用户硬件设备问题(如磁盘、内存满了)。
用户本地client版本不是正常版本,或本地有缓存,导致没有正确调用服务。
服务器存在异常(DNS故障、LB故障)。
代码中调用了第三方,第三方服务故障。
传统解决方案
为了能解决以上问题,我们通过建立监控系统,添加日志等方式尽可能记录用户/服务器任意时刻的情况,用于了解系统和事后调查解决问题。
于是有了腾讯/阿里云等运维监控,代码关键部分添加业务日志,引入loki/cls/sls等日志系统。更好一点的情况是日志还有traceId/requestId/userId等作为定位。
传统解决方案的缺陷
- 业务日志对于分析实际情况费时费力,无法一目了然。当出现问题时,需要进入日志面板调取当时的日志,然后根据搜索条件筛选日志,然后根据日志分析当时代码运行链路,参数和返回值是不是正常。
- 服务器当时环境和日志无关联。例如日志显示调取第三方接口失败时,那到底是当时服务器DNS解析问题,还是目标服务器服务故障。是应该让运维调查修复DNS,还是应该联系第三方。
- 日志格式不统一,覆盖率不够。由于各个项目,各个开发人员有自己的习惯,日志格式区别巨大,让解析日志有些困难。服务端和客户端有各自的日志规范,覆盖率有自己的标准,导致出问题时日志不够,无法完整回溯出问题时当时的情况。
对于以上问题,引入本文主题:OpenTelemetry相关技术栈。
二、OpenTelemetry
简介
OpenTelemetry是CNCF的项目,其统一了追踪、指标和日志的规范,定义了它们之间的联系。使用它以后,配合相应的面板,可以用于快速定位BUG,为解决问题节省时间和精力。
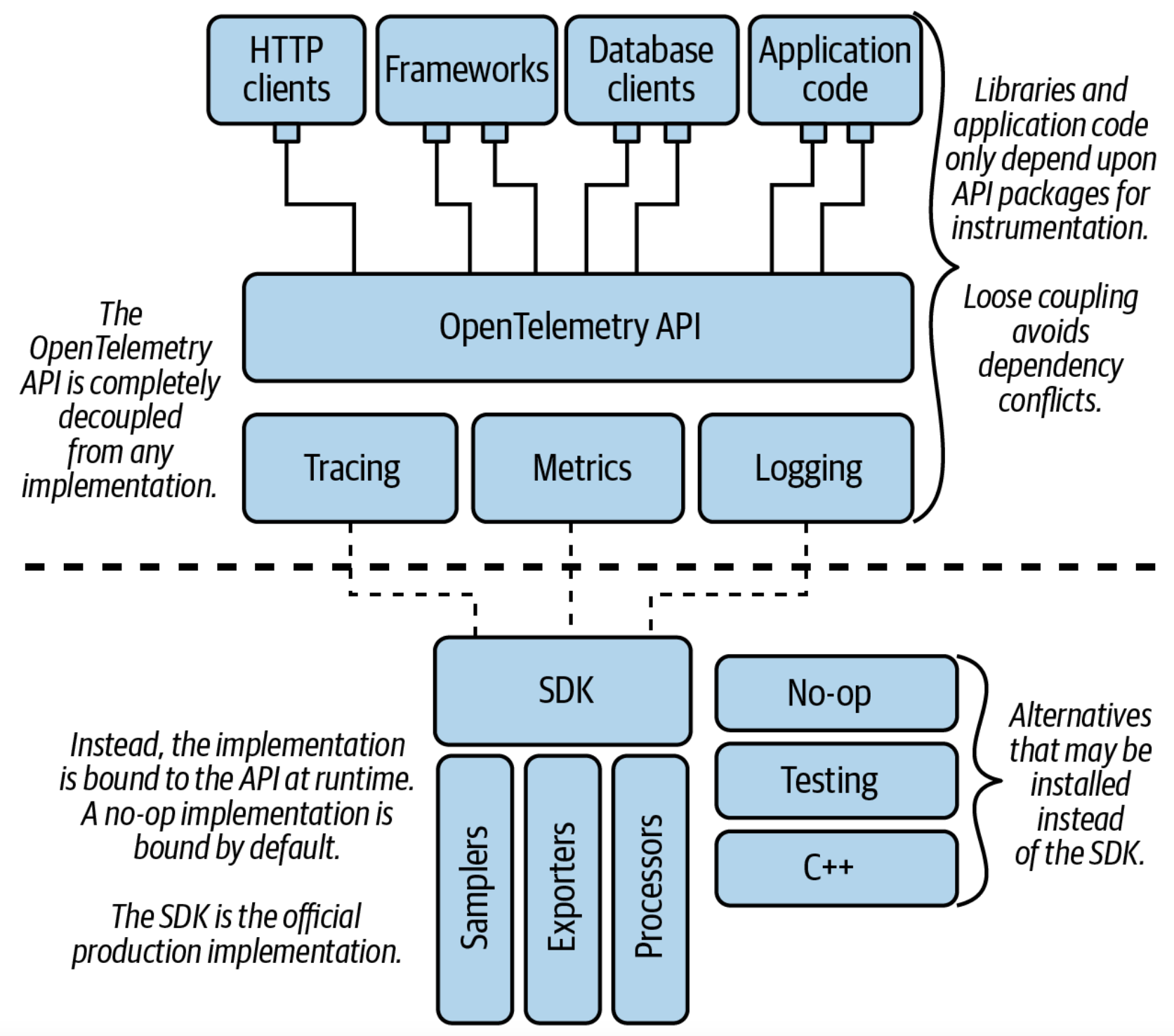
以上是OpenTelemetry的架构。从图中可知,可以在http client、应用代码、数据库客户端、业务框架/包中添加opentelemetry api打点,可以是跟踪点、指标点和日志点。打点实际被opentelemetry的sdk控制,sdk可以限制打点率,转发到其他数据接收服务,以及配置管道做预处理。
OpenTelemetry简要使用案例
OpenTelemetry本身只是一套在代码中打点的系统,作为举例,一下是php使用OpenTelemetry的方法。
- 建立管理面板服务,如granafa+loki/optl-collector+tempo/jaeker。
- 添加OpenTelemetry的sdk包。
- 配置OpenTelemetry类,配置相关配置,如导出服务地址、采样率等。
- 在需要打点的地方,如controller方法中,全局路由中添加打点,包括开始点和结束点。
- 运行项目,相关traces/logs/mertics将会在管理面板显示。
以下是granafa的loki日志主面板。
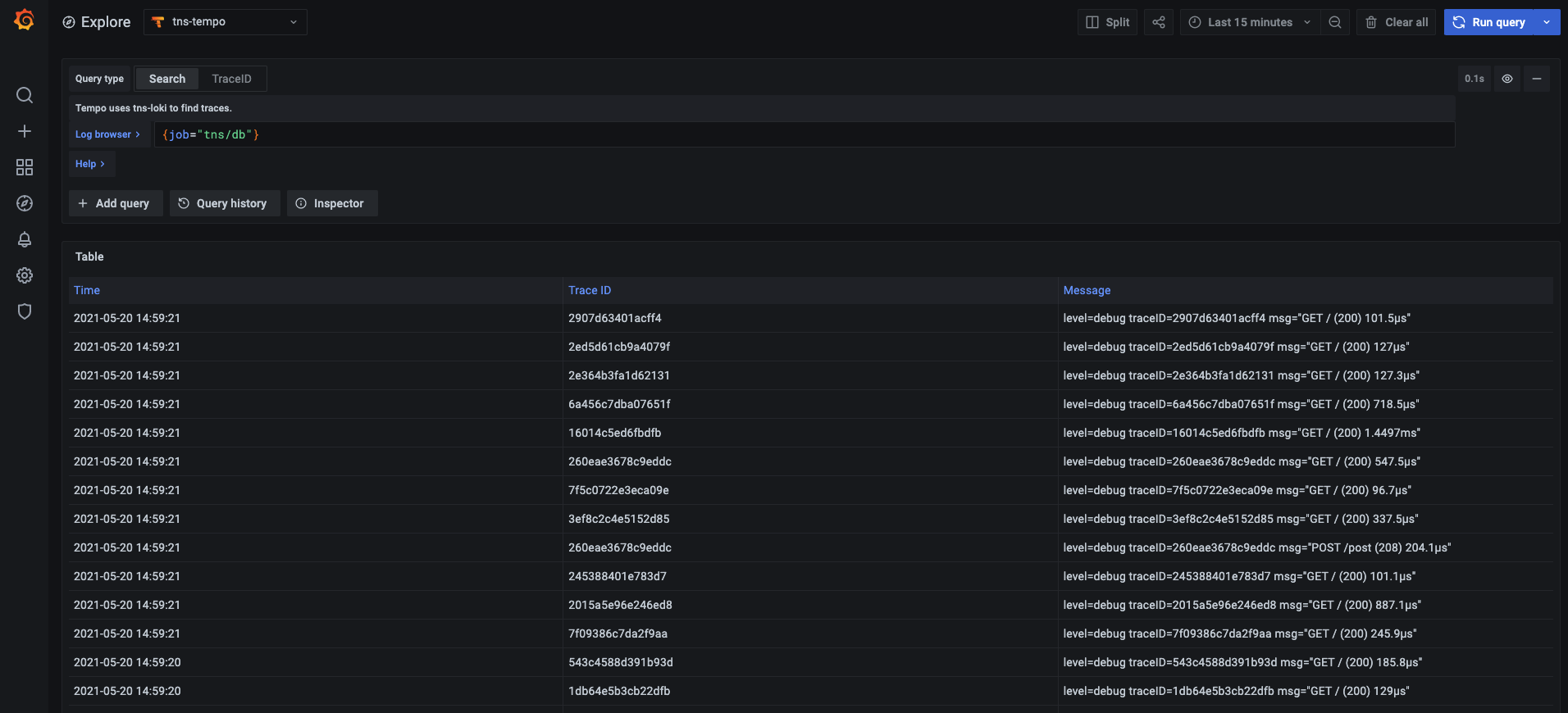
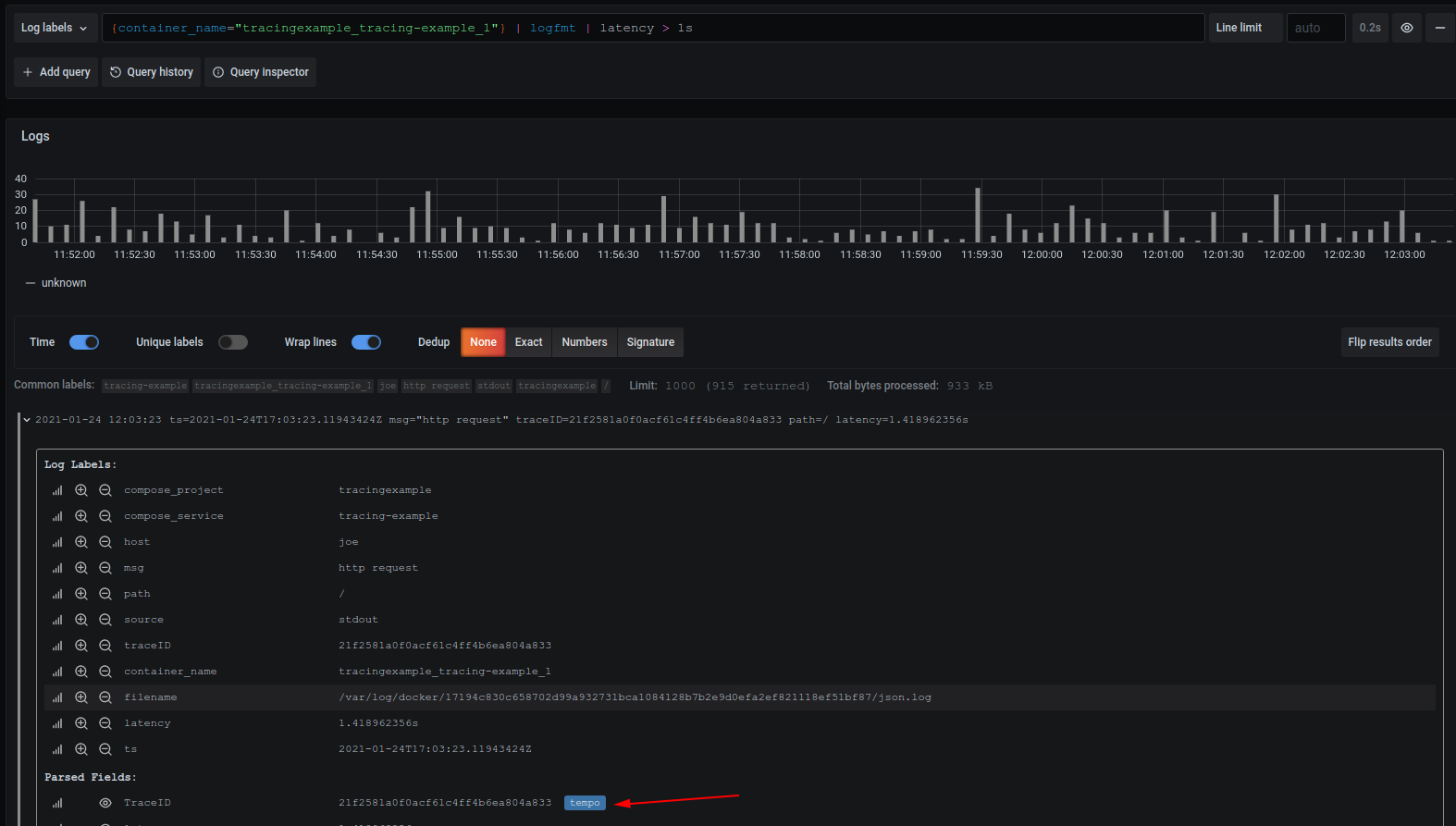
以下是granafa的loki日志详细面板,点击蓝色按钮可以跳转到trace面板中。
以下左边是loki日志面板,右边是trace面板,grafana可以使用tempo插件或jaeger插件做trace面板。
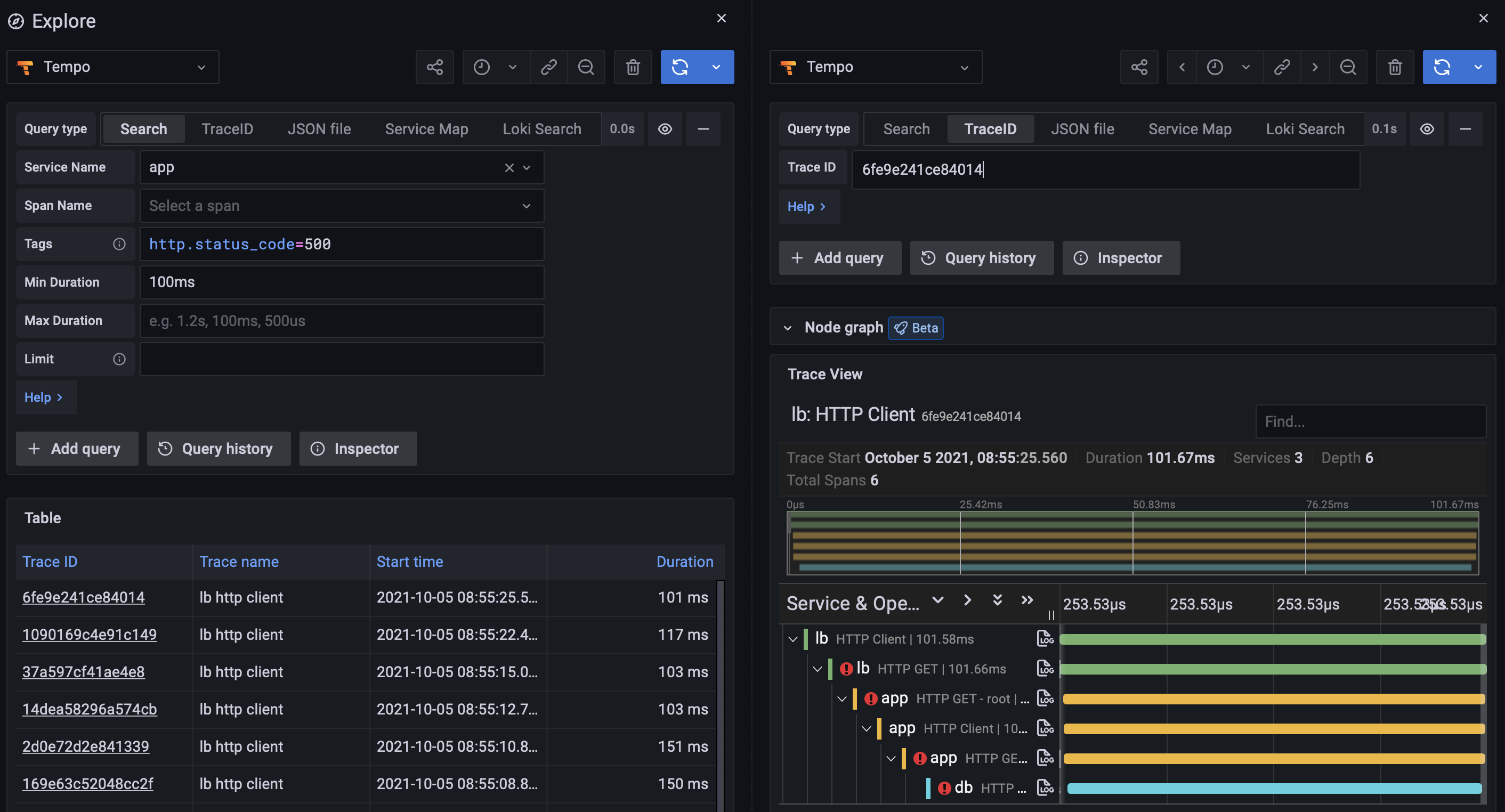
以下是trace面板中trace和service graph图。
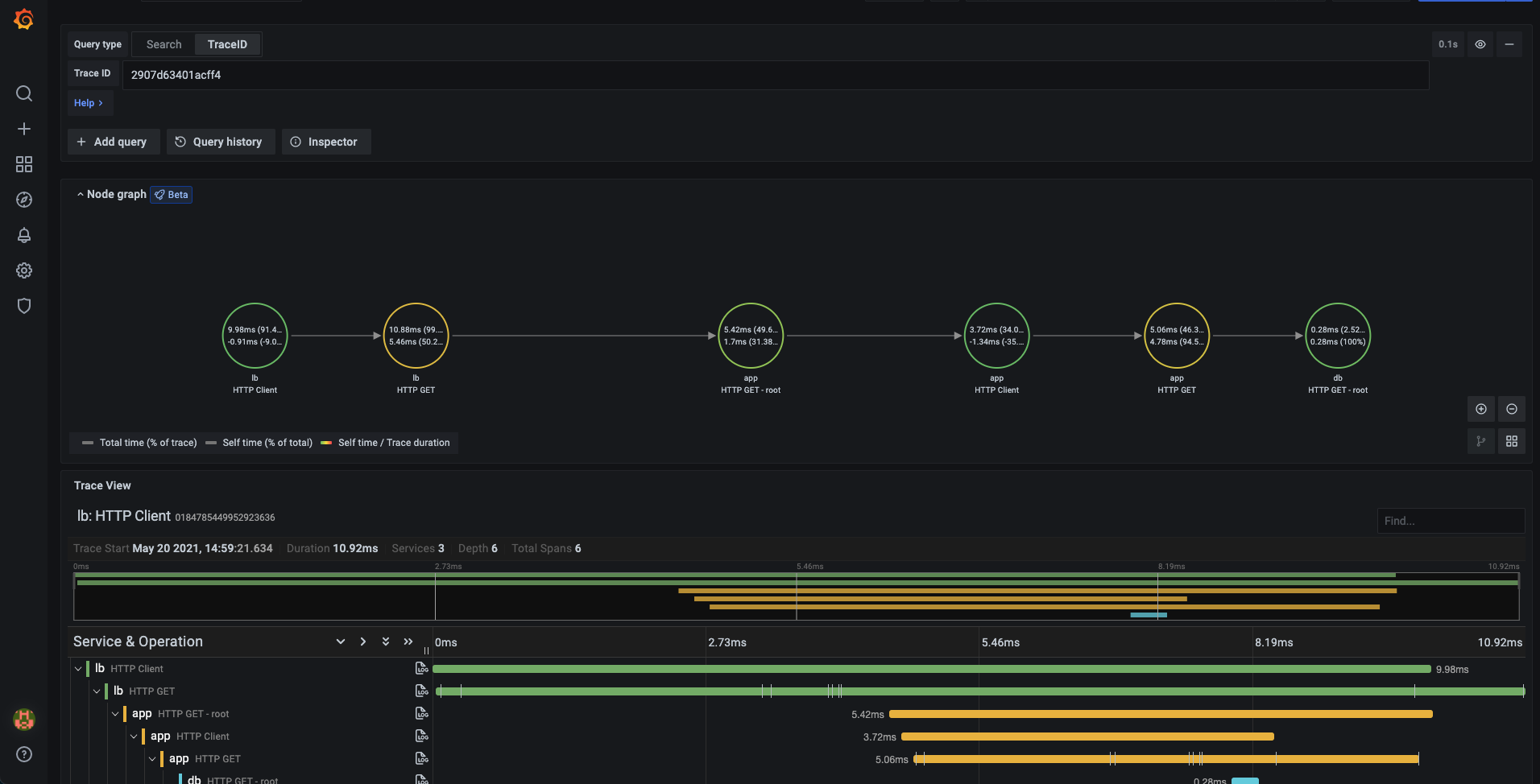
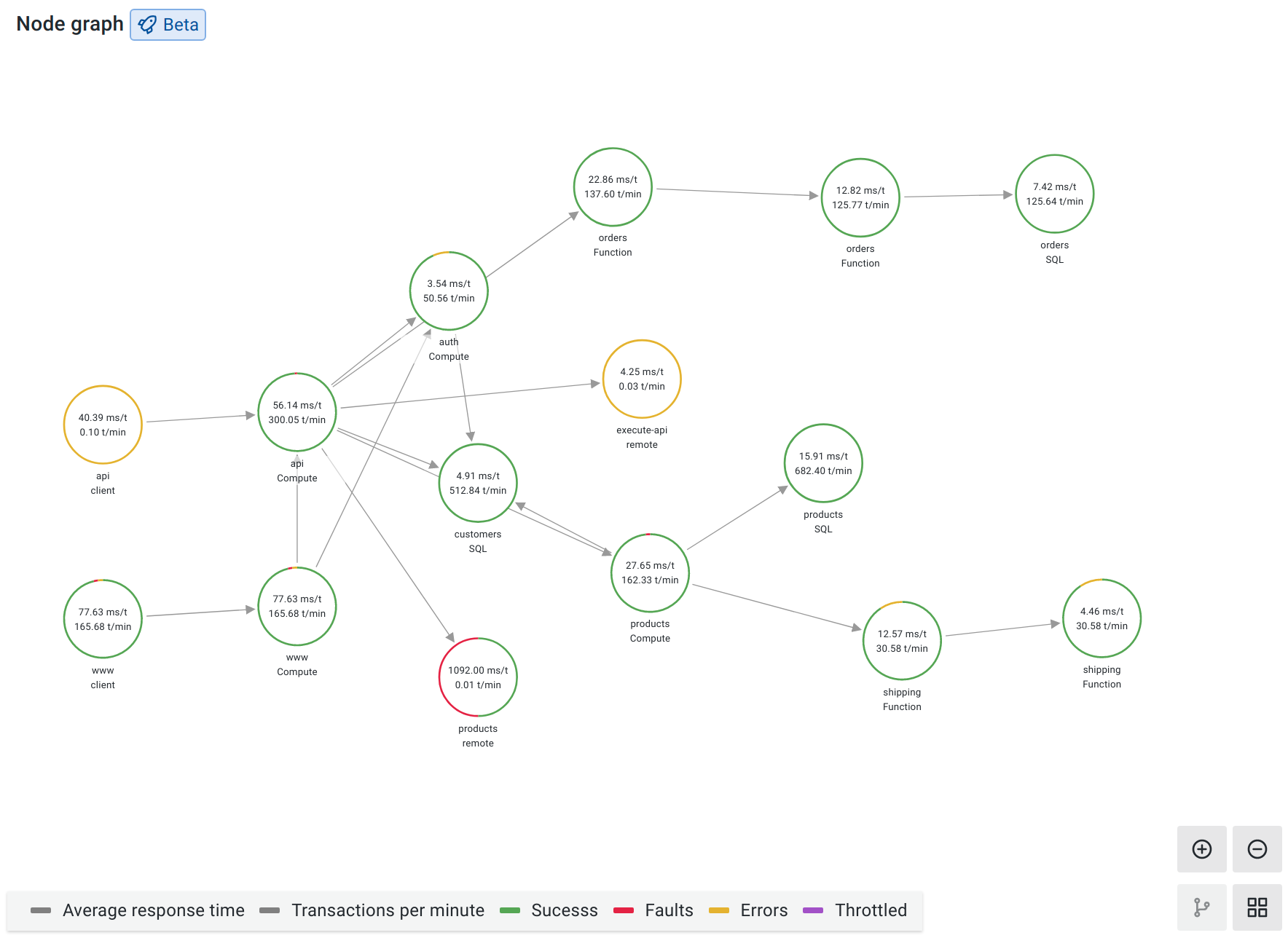
以下是trace面板中另一份service graph图,可以看到可以根据opentelemetry打点数据得到service关系图。
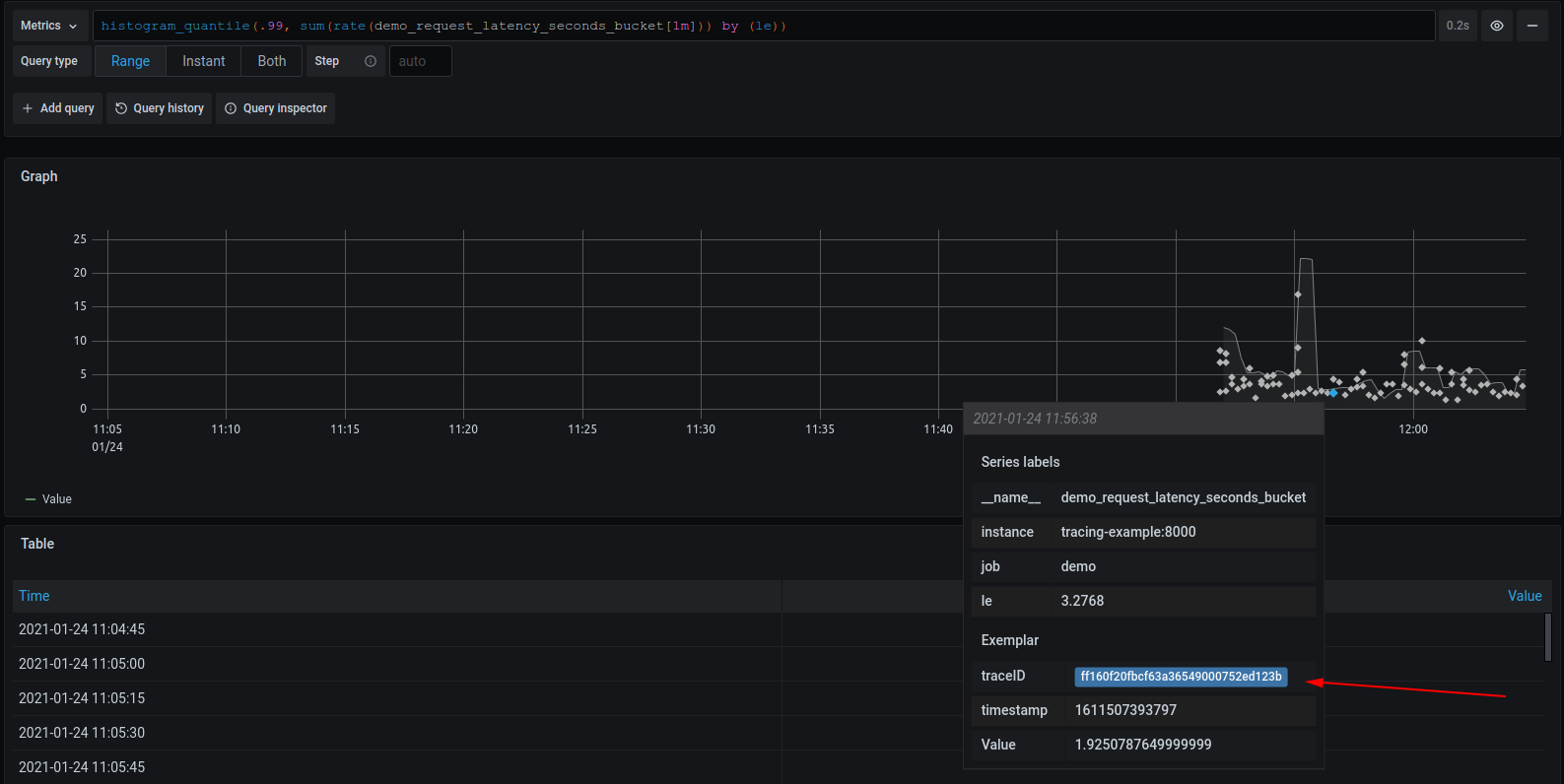
以下是granafa的prometheus面板,可全局查看所有接口服务质量,并可点击每个采集点进入trace面板分析改trace。
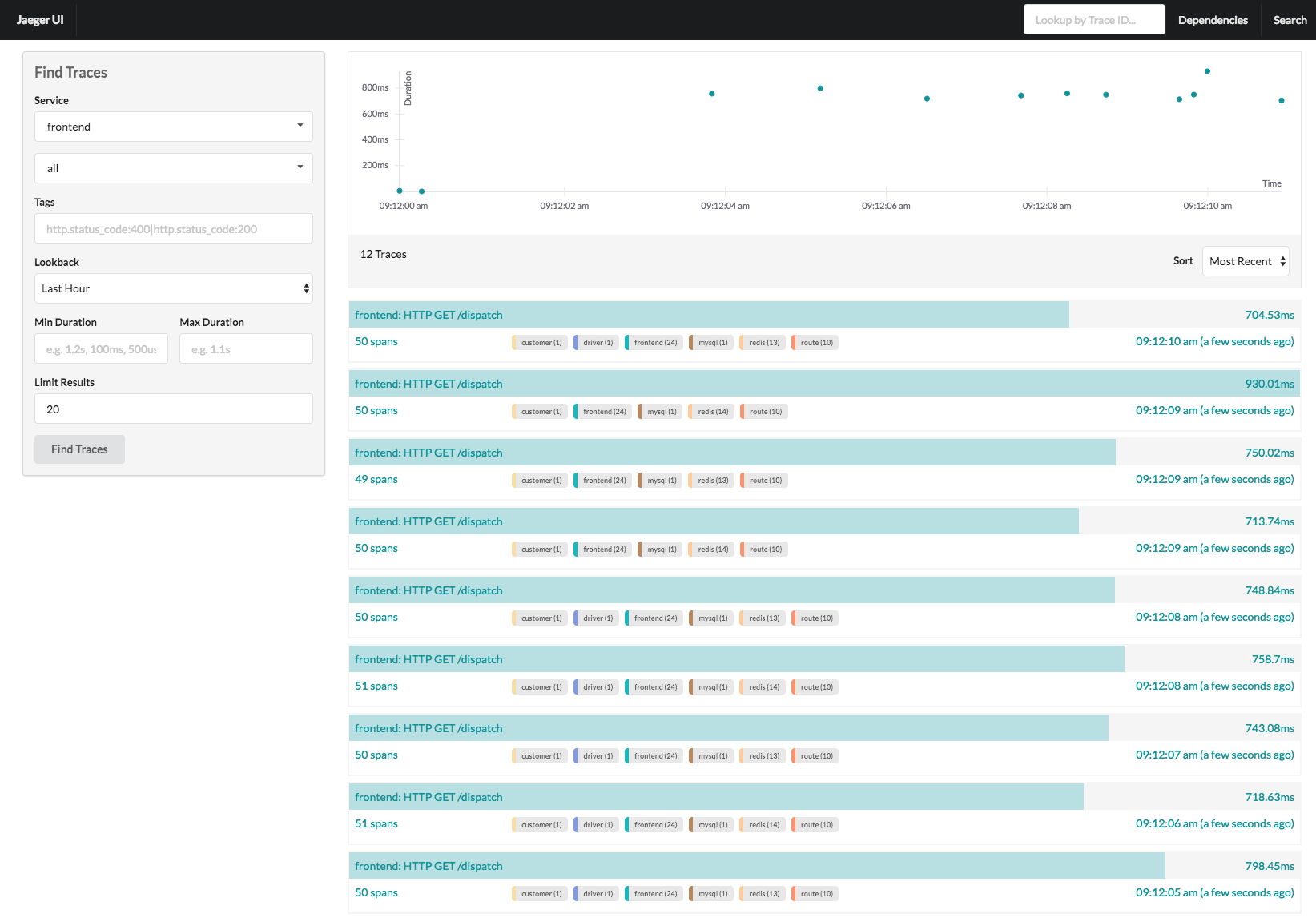
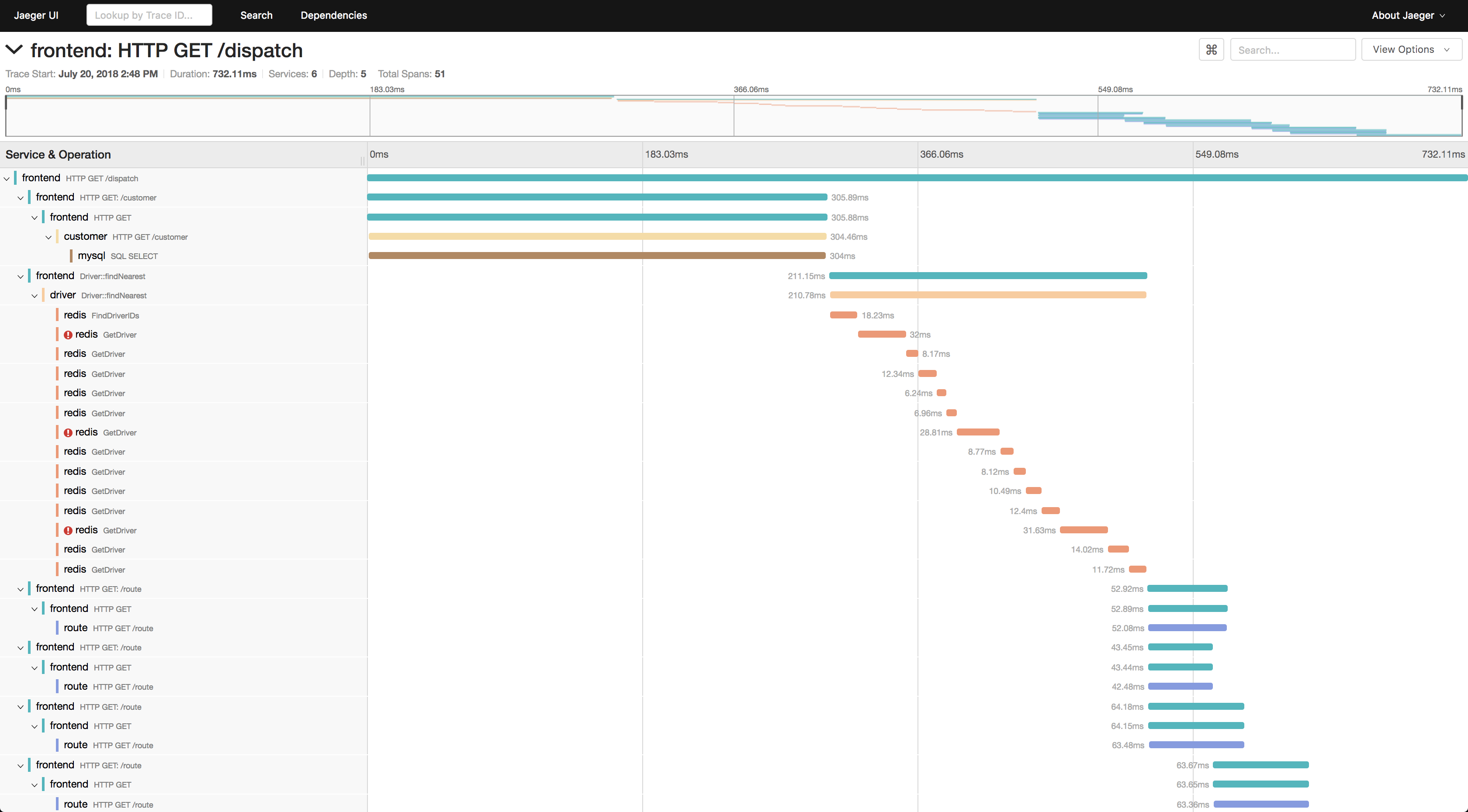
以下是jaeger的trace主面板。
以下是jaeger的trace详细面板。
使用OpenTelemetry有哪些好处
- 可随时监控每个接口请求消耗时间(APM)。
- 可扩展功能,根据用户名随时分析该用户/全体用户在应用使用的各个指标,使用时间、使用习惯等(RUM)。
- 可清楚查看接口调用栈,内部各个服务消耗时间,和之间的层级关系。
- 可直观了解各个微服务之间的联系。
- 出现问题时,可根据traces+metrics+logs,完全复现当时用户的情况(用户本地metrics+客户端RUM+后端接口APM+服务器metrics+所有logs)。并行traces、metrics和logs互相有关联,可互相跳转查看分析。
为什么选用OpenTelemetry而不是其他方案
- Opentelemetry是CNCF下的开源项目,CNCF下的项目还有:k8s、containerd、etcd、coredns、fluentd、helm、jaeger、prometheus、cilium、cni、cri-o、grpc、k3s、falco等。
- 由于是CNCF下的项目,和k8s等兼容问题一定有舒适的解决方案。
- Opentelemetry可以导出数据并接入到市面上大部分数据/日志服务商,如阿里云应用实时监控服务,腾讯云前端监控,腾讯云应用实时监控服务,DataDog,Sentry等。
- 配合Grafana+loki+tempo+prometheus+opentelemetry,可以建立一套完整的开源可观测全链路多维追踪服务。
- 消除无法复现bug这一情况,并不再只能靠review相关代码才能定位问题。实际上只要探针覆盖够,几乎不需要再花时间进行找日志+找对应代码+推测用户环境+推测服务器环境。
- 如果使用其他商业服务,存在收费和更换服务商问题。如果使用其他开源项目,不如就使用本项目,因为CNCF作为云服务时代主要基金会,OpenTelemetry后台够硬。
如何用这套方案调查解决本文开头的bug
- 获得用户名和使用应用的时间,根据用户名和时间查出相关日志。
- 点击该用户在前端/后端文章编辑的相关日志(RUM、APM),进入当前用户当前trace链。
- 会发现用户加载编辑页面UI花了1毫秒,调用接口花了20秒。或者发现用户在编辑页面待了10秒(RUM),但是接口还没返回(APM),用户就回到文章列表。
- 通过trace或prometheus,查看改接口当天整体情况,应该会发现只有该用户接口访问缓慢。由此即可确认是用户网络有问题。
三、各类人员能使用这套方案干什么
- 产品:可以根据前端RUM,根据前端收集的指标,如用户各模块使用时间、操作流程、使用习惯等来分析产品,对产品进行优化。
- 前端开发:前端可根据RUM进行前端性能监控,优化页面性能。
- 测试人员:可根据trace链基本定位bug责任方,可能页面加载时间有问题,可能后端接口无法服务,返回时间过长等。
- 运维人员:可根据服务器指标数据分析当前服务情况,如果整体服务变慢,可调查是否为服务器环境问题。同时由于接口跟踪可以携带服务器环境指标信息,有问题可以一目了然。
- 开发人员:可以观测整体服务情况。出问题时根据全链路跟踪信息,轻松定位bug位置和原因,快速解决bug。
